Hirad SabBody Troubles
Project Description
Body Troubles is an ongoing research on the proliferation and mediation of the digital body in the contemporary politics of images. Rhetorical, discursive, and disjointed, it is an attempt at locating the virtual body in the processes of production, circulation, and consumption of images concerning continuing computational advancements.
Figure 1.
17 minute video
Conceived in part using the state-of-the-art techniques in realtime computer graphics and machine learning, Figure 1. contemplates the affective and ethical implications of technological overreliance in the production of visual cultural artifacts. In this light, it probes the ensuing relational and sentimental shifts in the viewership of corporeality. Furthermore, it humors the public fascination with interpolative, inferential, and statistical means of generating bodily depictions.
Figure 1. was originally perceived as a 4-channel audiovisual installation. The preceding video is intended for supplementary online and screen-based viewing.

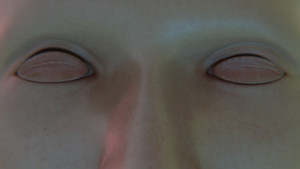
Never Seen in the Wild
High-quality image dataset of 100,000 computer generated faces
Never Seen in the Wild is the outcome of a generative system devised to perpetually output humanoid faces. Using a fully parameterized 3D model, paired with modular shaders, the system is capable of producing infinite facial variations. The parametrized model, is an aggregate of the most downloaded human models scraped from the web. In this way, it carries with it all the biases, assumptions, and engineered features that are perpetually replicated as these models are used in production. The availability and ease of use of such 3D models bring to question the veracity and accuracy of their creation and inherent biases; especially when utilized in the production and application of technologies that directly interact with the public: surveillance, facial recognition, and generative imaging. As such, Never Seen in the Wild is intended to operate as an ever-expanding dataset of synthetic faces to examine how biases carry over across different computational disciplines, and to spark a conversation on the means of inclusion and representational diversity in predictive models and their inescapable partiality.
At its current state, Never Seen in the Wild is comprised of 100,000 high-quality images with considerable variations in age, image background, and facial features. It consists of 25,000 unique humanoids with four variations in facial features, lighting, and background per individual. Every image is accompanied by 264 facial landmarks and occlusion annotations, camera metadata, and an 800-dimensional vector of the 3D model and shader parameters. Nevertheless, every data point is an assemblage of invisible prejudices made by the system and the makers of its source data.
Further reading:
Humans of Noyork
9 hour looping video
Humans of Noyork is 9 hours of pure content, 33.5 gigabytes of occupied storage space, 20,000 unique personalities, no eyes to stare back at you, and no stories to tell. It is a cult of personality, a makeup tutorial, a video log, and a lengthy ASMR video. It is voyeurism, entertainment, education, and gratification, simultaneously repulses and attracts. It lurks, disgusts, cringes, and appeals. It is available and accessible. And although it masks its presence under a facade of impartiality as content with no higher ambitions other than being content, it is the accumulation of years of preconception and biases in computational systems and computer graphics. More videos?
Artist Bio
Hirad Sab is an Iranian-American artist whose work explores the margins of digital aesthetics, internet culture, and technology. His amalgams occupy a precarious intersection of culture and the democratic nature of image circulation; an aesthetic trend that expands and mutates rapidly. Sab heavily features depictions of the human form, gesture, and activity in distinctly digital environments. The result is an emblematic oeuvre that resists easy classification.
Born in Tehran, Iran, Sab relocated to the U.S. in 2010. He pursued his MFA at UCLA and received his BS in Computer Science from the University of Utah. His work has been exhibited at The Wrong Biennale, Garage Museum of Contemporary Art, CHAO Art Center, and The LOW Museum of Contemporary Culture; with visual performances at MoMA PS1 and ICA London.